Introduction
The acceleration of hardware and software capabilities has allowed for the solution of highly complex and large problems in a variety of applications in science, technology, medicine, and engineering. High Performance Computing leverages computing power, in standalone or cluster form, with highly efficient software, message passing interfaces, memory handling capabilities to allow solutions to improve scalability and minimize run times. Finite Element Analysis inherently involves handling large matrix factorizations, inversions, and other manipulations across multiple dimensions. Depending on the solvers (iterative, direct, and so on) being used, the matrix operations involved may lead to very long run times on standalone workstations.
Computer Architecture
Computer Architecture is comprised of the structure and interaction of various entities of a computational system. Understanding the basics of Computer Architecture is essential to effectively utilize the High Performance Computing features available in OptiStruct.
A typical computational system consists of the Central Processing Unit (CPU) wherein all the basic calculations are performed. This is called Cores in typical workstations. The Cores/CPU’s are part of the physical processor in the Socket of the motherboard. A processor (in the Socket) can consist of multiple Cores/CPU’s. A single node can contain multiple sockets (each with a processor). A single Core/CPU can handle single or multiple connections in parallel with the software/operating system. These connections are called Threads, and typically a Core can only handle a single connection (Thread) at a time. If the Core/CPU is capable of hyper-threading, then multiple threads/connections between the Core/CPU and the software can exist in parallel.
Cluster
A computational cluster is a collection of nodes that are connected together to perform as a single unit. The tasks assigned to a cluster can be internally distributed and reconfigured by various software to nodes within the cluster.
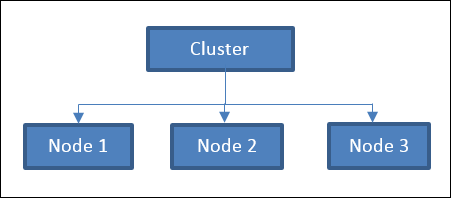
Figure 1: Typical Computer Architecture Layout - An example cluster with three nodes.
Node
A node is a computing machine/workstation/laptop within a cluster. It consists of different electrical and electronic components, such as Central Processing Units/Cores, memory, and ports that communicate with each other through complex systems and electronic pathways. Typically, a node consists of one or more sockets, which further contain one physical processor each.
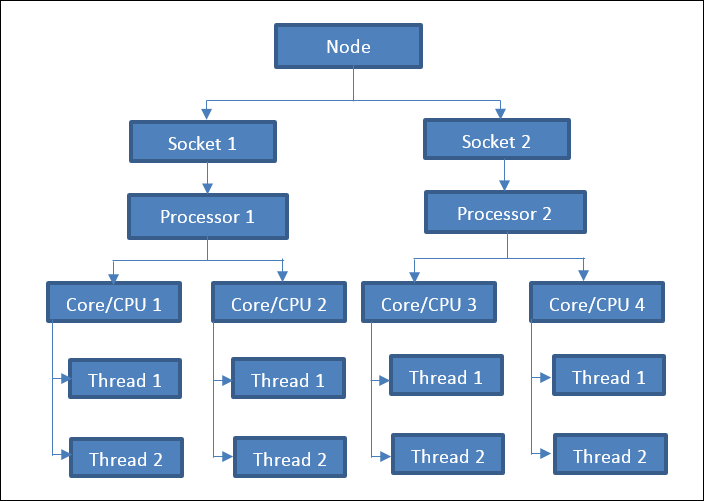
Figure 2: Typical Computer Architecture Layout - An example node with two sockets.
A Physical Process consists of single or multiple Cores/CPU’s. Unless a CPU is equipped with hyper-threading capabilities, a single Core/CPU can only handle one connection in the same CPU time interval. If hyper-threading is available, then multiple connections between the CPU and the software can exist in parallel. A Core/CPU is a full set of required data and hardware required to execute a program.
Serial vs Parallel Computing
Programs can be run in Serial or Parallel modes based on the specific hardware or software capabilities. Typically, Serial runs take place on a single logical processor with no memory distribution, whereas, Parallel runs occur on multiple logical processors with possibly shared or distributed memory depending on the type of parallelization implementation.
Serial Computing
|
Parallel Computing
|
Solution is divided into discrete instructions.
|
Solution is divided into sections, which are in-turn divided into discrete instructions.
|
Sequential Execution of discrete instructions one logical processor.
|
Parallel Execution of discrete instructions of all sections simultaneously on multiple logical processors.
|
At each point in the time-domain, only a single discrete instruction is executed.
|
At each point in the time-domain, multiple discrete instructions relating to multiple parts are executed simultaneously.
|
Run times are typically high compared to Parallel Computing.
|
Run times are typically lower than Serial Computing.
|
Implementation
High Performance Computing in OptiStruct allows the usage of multiple threads within a single shared memory system (SMP) to improve speedup, multiple nodes in a distributed memory system cluster (SPMD) via a message passing interface (MPI) implementation for further scalability, and/or a Graphics Processing Unit (GPU) via the NVIDIA CUDA implementation. The following High Performance Computing options are available in OptiStruct:
The parallelization options are available for a standalone systems, clusters, or GPU enhanced workstations.





