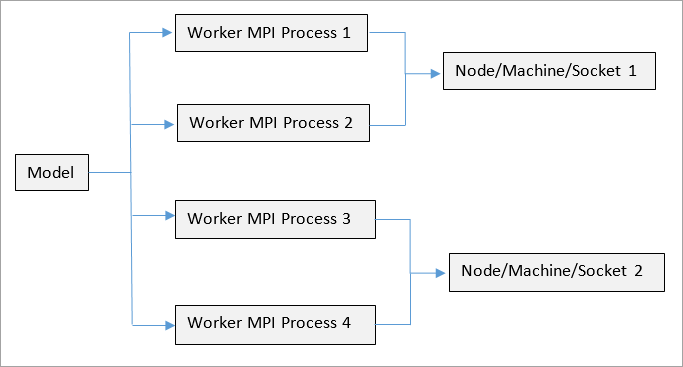
Load Decomposition Method (LDM) in OptiStruct can be used when a run is distributed into parallel tasks, as shown in Figure 1. The schematic shown in Figure 1 is applicable to a LDM run on multiple machines. The entire model is divided into parallelizable tasks, Table 2 lists the various supported solution sequences and parallelizable steps.
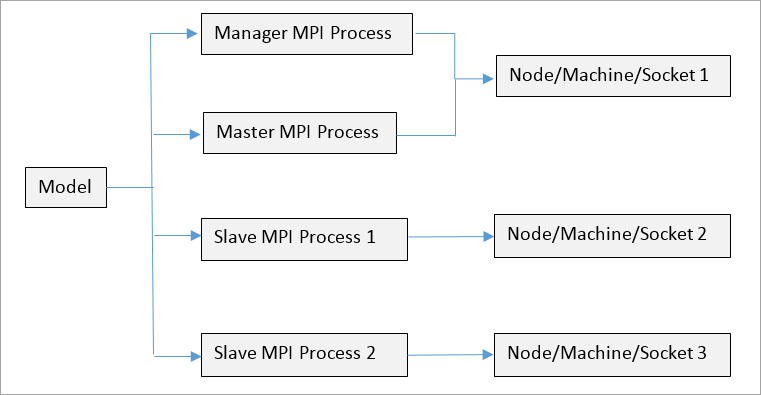
Figure 1: Example LDM setup with four MPI processes (-np=4). There are 3 nodes/sockets available for use.
In Load Decomposition Method, the model (analysis/optimization) is split into several tasks, as shown in Figure 1. The tasks are assigned to various nodes that run in parallel. Ideally, if the model is split into N parallel tasks, then (N+1) MPI processes should be spawned by OptiStruct for maximum efficiency (that is, -np should be set equal to N+1). The extra process is known as the Manager. The manager process decides the nature of data assigned to each process and the identity of the Master process. The manager also distributes input data and tasks/processes to various available nodes/machines. The manager process does not need to be run on a machine with high processing power, as no analysis or optimization is run by it. The Master process, however, requires a higher amount of memory, since it contains the main input deck and it also collects all results and solves all sections of the model that cannot be parallelized. Optimization is run by the Master process.
The platform dependent Message Passing Interface (MPI) handles the communication between various MPI processes.
Note:
| 1. | A Task is a minimum distribution unit used in parallelization. Each buckling analysis subcase is one task. Each Left-Hand Side (LHS) of the static analysis subcases is one task. Typically, the static analysis subcases sharing the same SPC (Single Point Constraint) belong to one task. Not all tasks can be run in parallel at the same time (For example: A buckling subcase can not start before the execution of its STATSUB subcase). |
| 2. | The manager and master processes can be run on the same node/socket. In a cluster environment, this can be accomplished by repeating the first node in the appfile/hostfile in a cluster setup. If, as recommended, -np is set to N+1, then N+1 MPI processes are spawned and both manager and master processes are assigned to the first two nodes on the list (which in this case will both be node 1). The -np option, appfile/hostfile are explained in the following sections. |
|
Supported Solution Sequences for LDM
OptiStruct can handle a variety of solution sequences as listed in the overview. However, all solution sequences cannot be parallelized. Steps like Pre-processing and Matrix Assembly are repeated on all nodes, while response recovery, screening, approximation, optimization and output of results are all executed on the Master node.
Solution Sequences that Support Parallelization
|
Parallelizable Steps
|
Non-Parallelizable Steps
|
Static Analysis
|
 Two or more static Boundary Conditions are parallelized (Matrix Factorization is the step that is parallelized since it is computationally intensive.) Two or more static Boundary Conditions are parallelized (Matrix Factorization is the step that is parallelized since it is computationally intensive.)
Sensitivities are parallelized (Even for a single Boundary Condition as analysis is repeated on all slave nodes).
|
Iterative Solution is not parallelized. (Only Direct Solution is parallelized).
|
Buckling Analysis
Note:
Preloaded Buckling Analysis (STATSUB(PRELOAD) in a buckling subcase) is not supported with Load Decomposition Method.
|
Two or more Buckling Subcases are parallelized.
Sensitivities are parallelized.
|
|
Direct Frequency Response Analysis
|
Loading Frequencies are parallelized.
No Optimization.
|
|
Modal Frequency Response Analysis
|
Loading Frequencies are parallelized.
|
Modal FRF pre-processing is not parallelized.
Sensitivities are not parallelized.
|
Table 2: Load Decomposition Method - Parallelizable Steps for various solution sequences
As of HyperWorks 11.0, the presence of non-parallelizable subcases WILL NOT make the entire program non-parallelizable. The program execution will continue in parallel and the non-parallelizable subcase will be executed as a serial run.
MPI Process Assignment (in a cluster)
In a cluster environment, the manager process is always run on the first listed node in the appfile/hostfile. The master process is run on the second listed node and the remaining processes are assigned to the remaining nodes. If there are more MPI processes than nodes, then the extra processes are randomly assigned to the remaining nodes. If there are more nodes when compared to MPI processes, then some of the extra nodes are idle during the run.
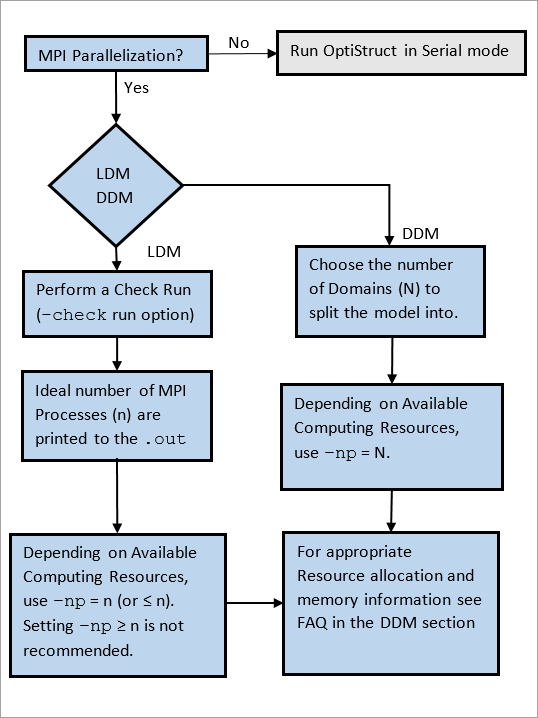
Caution should be exercised in setting the number of spawned MPI processes (-np). If –np is set greater than N+1 (indicated in the .out file), then more MPI processes are spawned than there are parallelizable tasks for the LDM run. In such instances, these MPI processes utilize computational resources but do not contribute to the solution, thereby increasing runtimes.
If –np is set lower than N+1 (indicated in the .out file), then fewer MPI processes are spawned than there are parallelizable tasks for the LDM run. This may be acceptable if you are limited by hardware (node/socket) availability. However, if you have a sufficient number of nodes (at least N+1), then it is highly recommended to set –np equal to N+1 to maximize scalability.
MPI Process Type
|
Functions
|
Master Process
|
Consists of all non-parallelizable tasks
Optimization is run
|
Slave Process(es)
|
Consists of parallelizable tasks
Input deck copies are available
|
Manager Process
|
No tasks are run in this process, it manages the way nodes/sockets are assigned tasks.
Manager process makes multiple copies of the input deck for the slave processes.
|
Table 3: Types and functions of the MPI Processes
This assignment is based on the sequence of nodes that you specify in the appfile. The appfile is a text file which contains process counts and the list of programs. Nodes can be repeated in the appfile.
Frequently Asked Questions (LDM)
LDM parallelization is based on task distribution. If the maximum number of tasks which can be run at the same time is N, then specifying (N+1) processes is recommended (the extra process is the manager process). Using greater than (N+1) nodes will not improve the performance, and may possibly adversely affect run time.
For LDM runs, the .out file suggests the number of MPI Processes you can use, based on your model.
In a cluster environment, when there are only M physical nodes/machines available (M < N), the correct way to start the job is to list M+1 nodes/machines in the hostfile/appfile (the first node is repeated). The manager process requires only a small amount of resources and can be safely shared with the master process:
The way to assign such a distribution is repeating the first physical host in the hostfile/appfile.
For example: hostfile for Intel MPI can be:
Node1
Node1
Node2
Node3
…….
| Note: | For Frequency Response Analysis any number of MPI Processes may be specified via -np (up to the number of loading frequencies in the model); however, this should be less than or equal to the number of physical processors (or sockets) in the cluster. |
|
No. Memory estimates for serial runs and that of a single process in a LDM run are the same. They are based on the solution of a single (most demanding) subcase.
|
Yes. Disk space usage for each process will be smaller, because only temporary files related to task(s) solved for that particular process will be stored. But the total amount of disk space (for all MPI processes combined) will be larger than that in the serial run and this is noticeable, especially in parallel runs on a single shared-memory machine.
|
|