The following guidelines apply to all entries in the bulk data section:
| • | Data may contain 80 characters per line at most. All characters after the 80th are ignored. The exceptions are the INCLUDE data entry and the Free format. SYSSETTING,CARDLENGTH, can be used to change the number of characters allowed in each line. |
| • | “Tab” spaces are not allowed and may lead OptiStruct to error out, if present. |
| • | Each line of data contains up to nine fields in one of the three accepted formats: |
Fixed Format
Each field consists of eight characters (shown below).

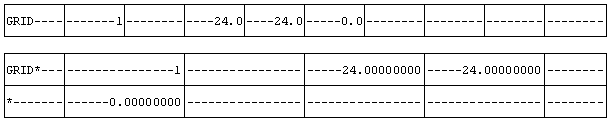
Large Field Fixed Format
Each field consists of 16 characters; two consecutive lines form nine fields, similar to other formats (shown below). Large field format is recognized by the first character after the keyword, or by the first character in each continuation line, which must be ‘*’. The second line (‘half line’), if present, must also contain ‘*’ in the first column. The first and last field in each half line is eight characters long. The last field on each first half-line and the first field on each second half-line are ignored.
 The following examples show the same card in fixed and large field formats: The following examples show the same card in fixed and large field formats:
Free Format
Fields are separated by commas; blank characters surrounding commas are not significant. Two consecutive commas define empty (blank) fields. If a comma is present in a line of data, it is assumed to be free format data. Continuation lines for free format start with a blank, '+' or '*'.
Large field free format and short field free format are available, but there is no limit on the length of entries, and all floating numbers are read and stored with full precision (64-bit REAL*8) in either case. The only difference between large and short free format is that the latter allows for 8 data fields in each line (in positions 2 – 9), while the former allows for 4 data fields per line (similar to the large field fixed format detailed above).
|
| • | If there is a comma within the first 10 characters in a line, the line is assumed to be in free format; otherwise, if there is an '*' immediately after the card name or a continuation line starts with '*', then the line is accepted as large field fixed format. All other lines are read in as fixed format. |
| • | Use of fixed format limits the range of integer data (-9,999,999 .. 99,999,999) and the accuracy of floating point numbers, but does not influence the internal storage of data – in particular all floating point numbers are always read and stored with full precision (64-bit REAL*8). |
| • | Bulk data is always limited to 9 fields per line. Content of 10th field and the first field of each continuation line are silently skipped when fixed format is used (other codes can use these fields for special purposes, such as to mark matching continuation lines). |
| • | Extensions of free format (which may allow more than 9 fields in a line) are not accepted. An error message is issued when a free format card contains more than 9 fields. This error can be disabled (changed to non-fatal warning) through the use of SYSSETTING,SKIP10FIELD. |
| • | Dollar signs, $, in any column denote comments. All characters after the dollar sign until the end of the line are ignored. Dollar signs can only appear in quoted files names. |
| • | Lines which begin with two slashes, //, or a pound symbol, #, are read as comment lines. Blank lines are also assumed to be comment lines. |
| • | The full keyword of each bulk data entry must be given starting from the first column. Abbreviated keywords are not allowed. |
| • | The format of most bulk data entries is similar to that for Nastran. Not all entry options are supported by OptiStruct. Consult the list of fields and options supported. |
| • | Continuation entries must follow the parent entries. If the first character of any entry is either a blank, a ‘+’, or an ‘*’, it is treated as a continuation of the previous entry. If the entire line is blank, it is treated as a comment line. |
| • | An ENDDATA entry or end-of-file denotes end of data. Lines after the ENDDATA entry are ignored. |
| • | All Bulk Data entries must appear after the BEGIN BULK statement in the input data. |
| • | The content of the tenth field in each card, and that of the first field in each continuation card, is disregarded. |
| • | Each entry can be placed anywhere within the field. For example, blanks preceding and following an entry are ignored, except the keyword entry, which must be left justified in its field. |
| • | No entry can contain blanks within the data. This is also required for character entries. |
| • | Character entries (labels) must start with a letter or underscore. In some cases, OptiStruct will accept label consisting of digits only. However, this approach is discouraged, remove non-numeric character (example, underscore) to such labels. |
| • | Numeric entries must start with a digit, ‘+’ or ‘-‘. |
| • | Integer entries may not contain a decimal point or an exponent part, and must fit in the range of values allowed for INTEGER*4 (usually –2**31<x<2**31). |
| • | Integer entries representing User IDs (e.g. for GRID, element, material, etc.) must contain up to 8 digits, i.e. be within 1-99,999,999 range. |
| • | Input decks using parts-instances approach can have fully qualified IDs in fields expecting a User ID. Such data will consist of a part name followed by a period (dot) and integer ID. However, not all fields, and not all cards accept such fully qualified ID, in particular Card ID (usually second field in the first line) must always be integer form only. |
| • | Integer data placed in the field reserved for real valued data is accepted and converted to a double precision. However, certain fields have alternate functions where the nature of the number entered indicates the desired function; one function requires an integer while the other requires a real number – in this case, no conversion is performed. |
| • | Real valued data can be entered without exponent part, with exponent part and explicit letter ‘E’ or ‘D’ or with exponent part starting with a sign (without ‘E’ or ‘D’). All real values are stored internally as double precision data (64-bit REAL*8) without regards to which format was used to enter them. Following are valid examples of input for real valued data: |
1.
0.1
.1
+.1
-0.1
1e5
1e+5
1+5
1.0E-5
.1d-5
.00001-05
| • | Character entries longer than eight characters are silently truncated in large field and free field formats, with the exception of file names on the INCLUDE entry (see documentation for INCLUDE entry) and the “LABEL’ field on DESVAR, DRESP1, DRESP2, DRESP3, and DTABLE entries (allows up to 16 characters). |
| • | Character entries are case insensitive, including card names. However, character fields which contain user labels (e.g. DESVAR, DRESPx, etc.) preserve case. |
| • | Continuation lines do not have to be in the same format as the parent entries. It is allowed to mix lines in different formats within a single bulk data card. |
| • | Both lines in a long format have to be the same type - either both fixed format or both free format. |
| • | The second half-line of the long format (if blank) can be skipped, only if it is the last line in the card data or if the next line is in a short format (fixed or free). |
| • | When the next continuation line is in a long format, then an empty half-line must be present and contain either '*' or '*,' for fixed or free long format, respectively. It is a common error to skip such half-line, but this results in the next half-line to be used in fields 6-9. |
| • | Invisible tab characters are equivalent to the number of spaces needed to advance to the nearest tab stop. Tab stops are placed at the beginning of each eight-character field. Use the SYSSETTINGS,TABSTOPS option to change this value, for example, to tab stops at 4-character fields. |
Replication of GRID data
| • | Replication is a limited data generation capability which may be used for GRID data only. |
| - | Duplication of fields from the preceding GRID entry is accomplished by coding the symbol =. |
| - | Duplication of all trailing fields from the preceding entry is accomplished by coding the symbol ==. |
| - | Incrementing a value from the previous entry is indicated by coding *x or *(x), where x is the value of the increment. “x” should be a real number for real fields or an integer for integer fields. The parentheses will be ignored and removed. |
| - | Only the fields for ID, CP, X, Y, Z, and CD can be incremented. The PS data cannot be incremented. |
| - | Replication data can follow other replication data. |
Entered entries:
GRID,101,17,1.0,10.5,,17,3456
GRID,*1,=,*(0.2),==
GRID,*100,,=,=,*10.0,==
GRID,20,17,==
Generated entries:
GRID
|
101
|
17
|
1.0
|
10.5
|
|
17
|
3456
|
GRID
|
102
|
17
|
1.2
|
10.5
|
|
17
|
3456
|
GRID
|
202
|
|
1.2
|
10.5
|
10.0
|
17
|
3456
|
GRID
|
20
|
17
|
1.2
|
10.5
|
10.0
|
17
|
3456
|
Removal of duplicate entries
| • | Removal of duplicate entries is a limited to GRID, CORDxx, and base MAT/PROP entries only (MATX, MATT, and PROPX entries do not allow duplicates). |
| • | To be considered duplicates, the GRID ID, CP, CD, and PS fields must be the same. The GRID coordinates should be the same within the setting determined by PARAM,DUPTOL. |
| • | For the coordinate information to be considered duplicate, the CID and GID must be the same and the vector components and axis locations must be the same within the setting determined by PARAM,DUPTOL. |
| • | The removal of duplicated GRID data is performed after any GRID data is generated using the GRID replication feature. |
| • | For all other cards which require a unique ID, it is an error if any given ID appears more than once. However, to facilitate application of changes resulting from optimization, it is possible to redefine content of some cards using a separate file defined with ASSIGN,UPDATE. |
See Also:
The Input File
Bulk Data Section
Bulk Data Entries by Function





